MR physicist’s last exam – LLM4MR

Large Language Models (LLMs) like ChatGPT are drafting emails, designing apps, and even outsmarting us at trivia. Recently, also first artificial scientists popped up and we wondered if we as MR sequence developers are also soon out of business. So why not test the LLMs by let them code pypulseq sequences.
We did so one year ago in the article Exploring GPT-4 as MR Sequence and Reconstruction Programming Assistant, which showed that it is possible to prompt GPT into being an MR sequence developer. But it needed also detailed instructions for complex sequences, for example a spin echo EPI sequence was never coded properly by GPT, only when a detailed instruction was given.
Now more than a year of new developments by the AI folks passed, and many more models are now available. So let’s see which language model wins the LLM4MR challenge in coding the best MRI sequence.We gave a human student and 6 different LLMs (ChatGPT-4o, DeepSeek-R1, Claude Sonnet 3.7, Grok-3, Grok-3-think, and Copilot) the same task:
„Code a spin echo epi (64×64, fov=(0.2,0.2,0.08) m, TE=150ms)!“
All of them had one or two coding errors so that code could not be executed. The error message was feed back to the LLM, and the first running code was plotted and simulated.
First a „human“ reference:
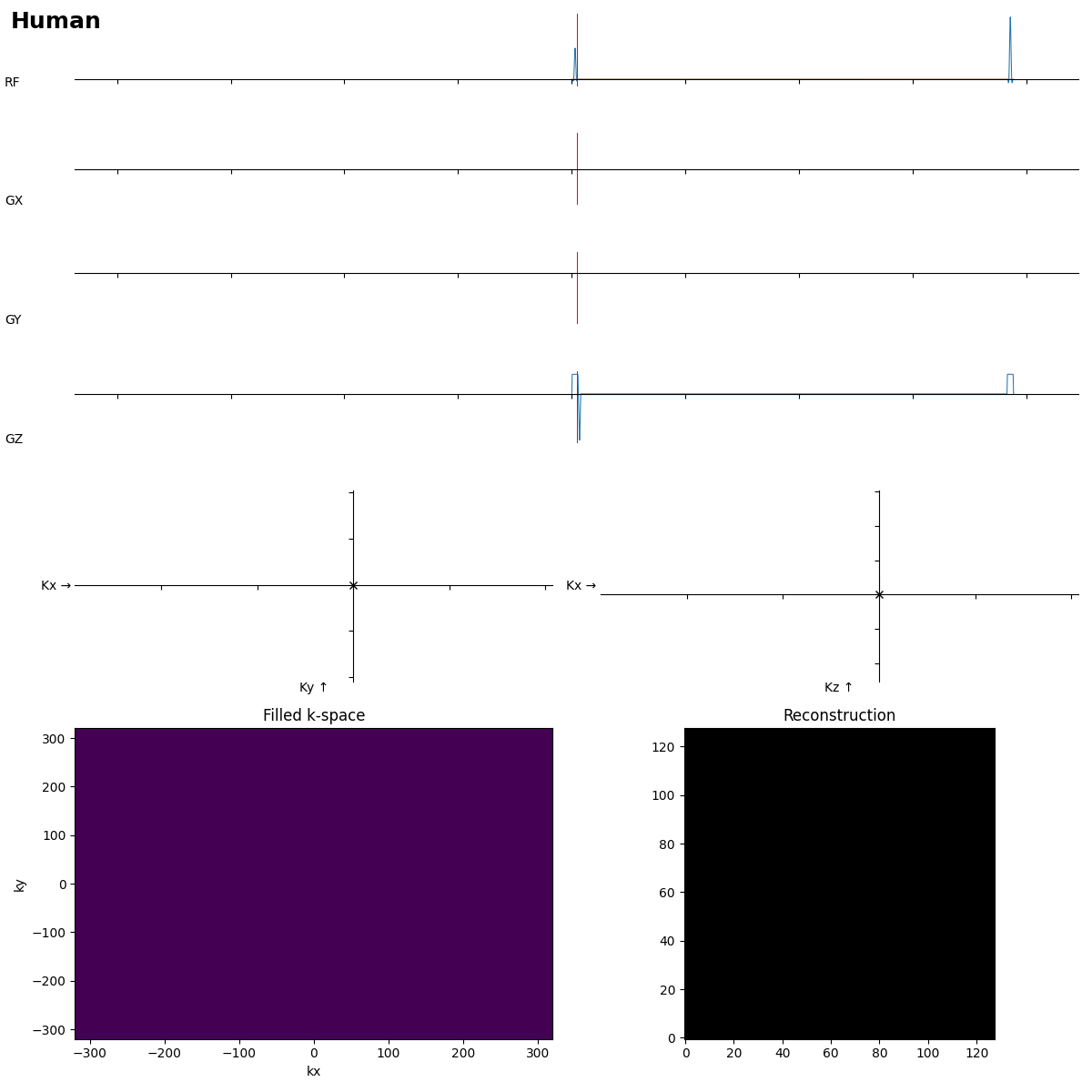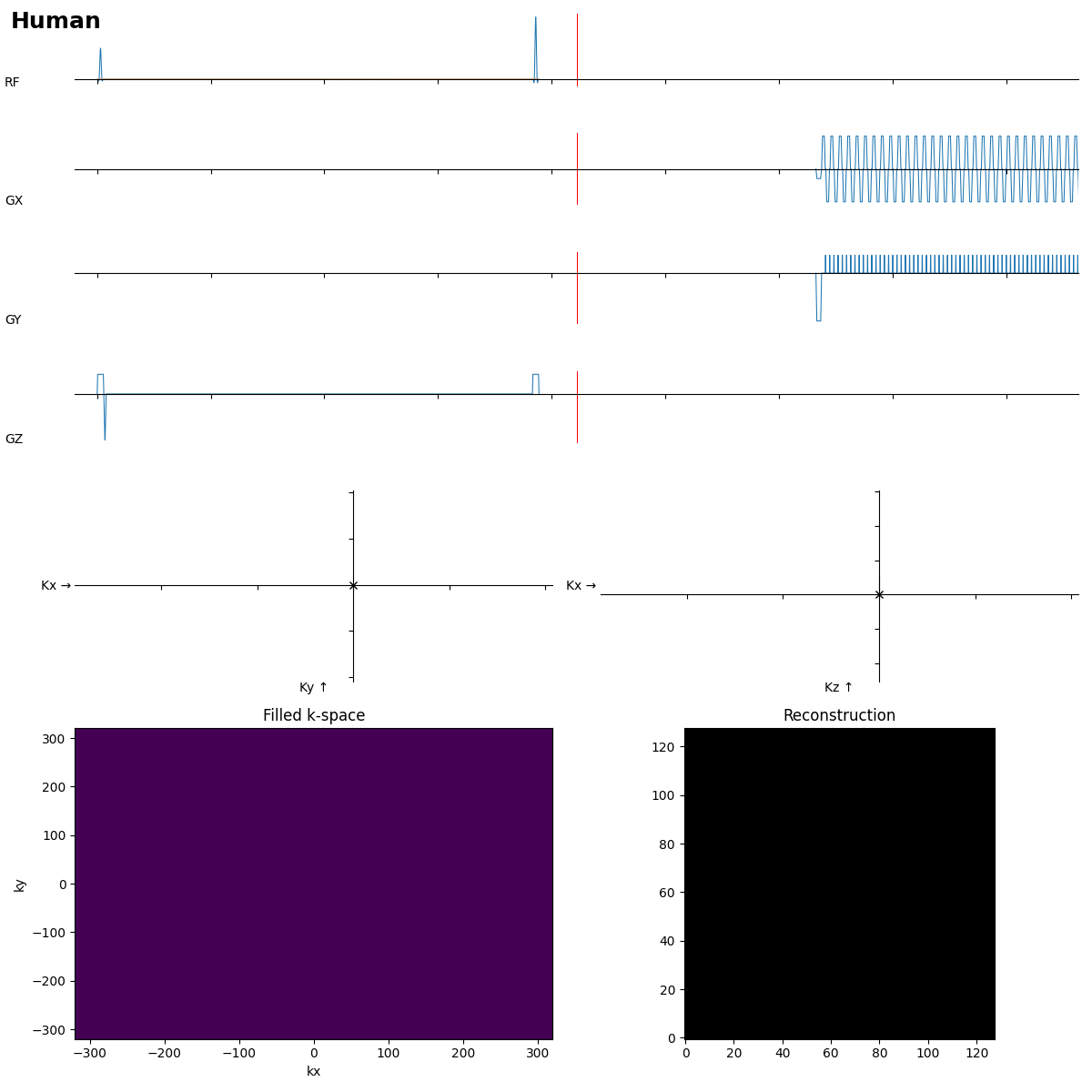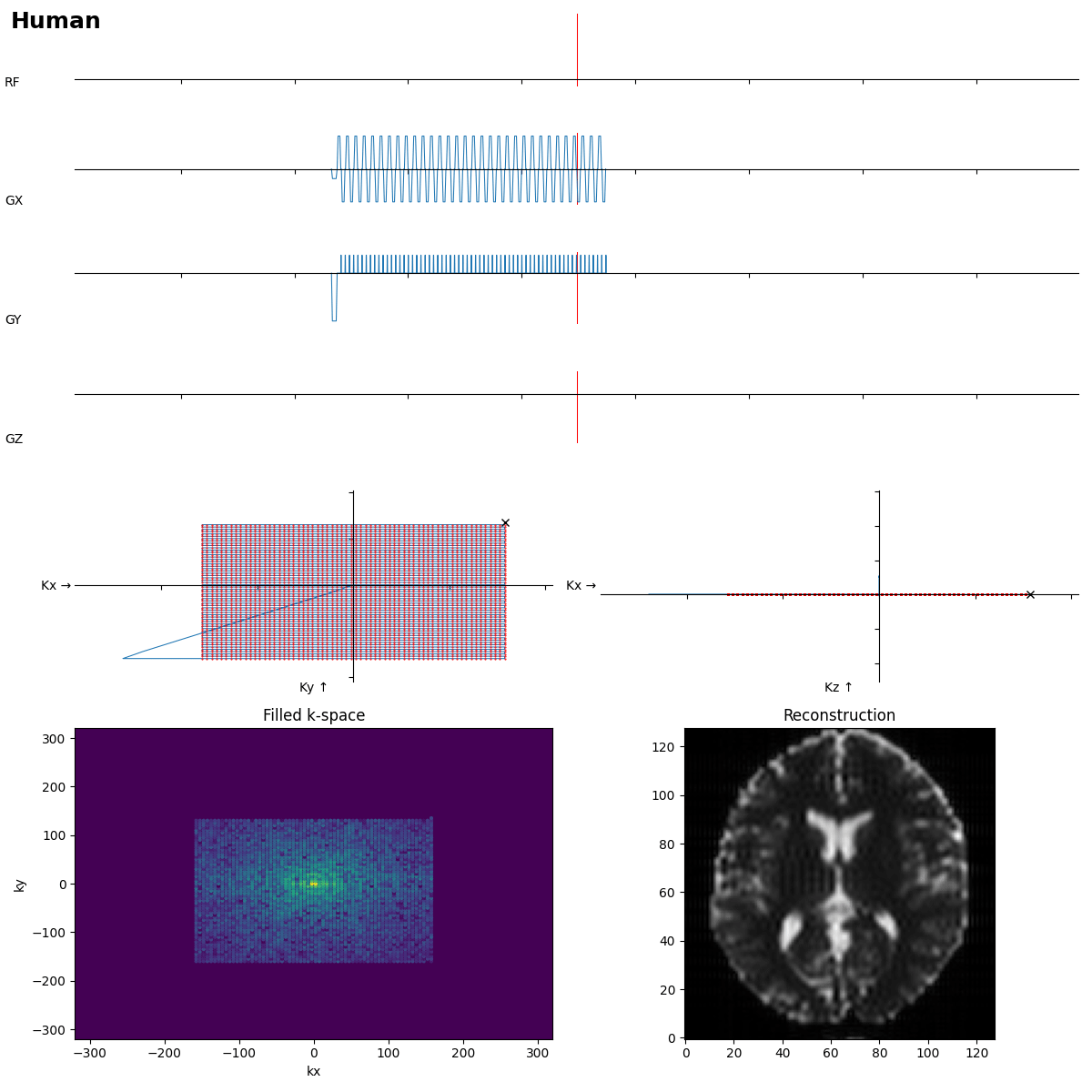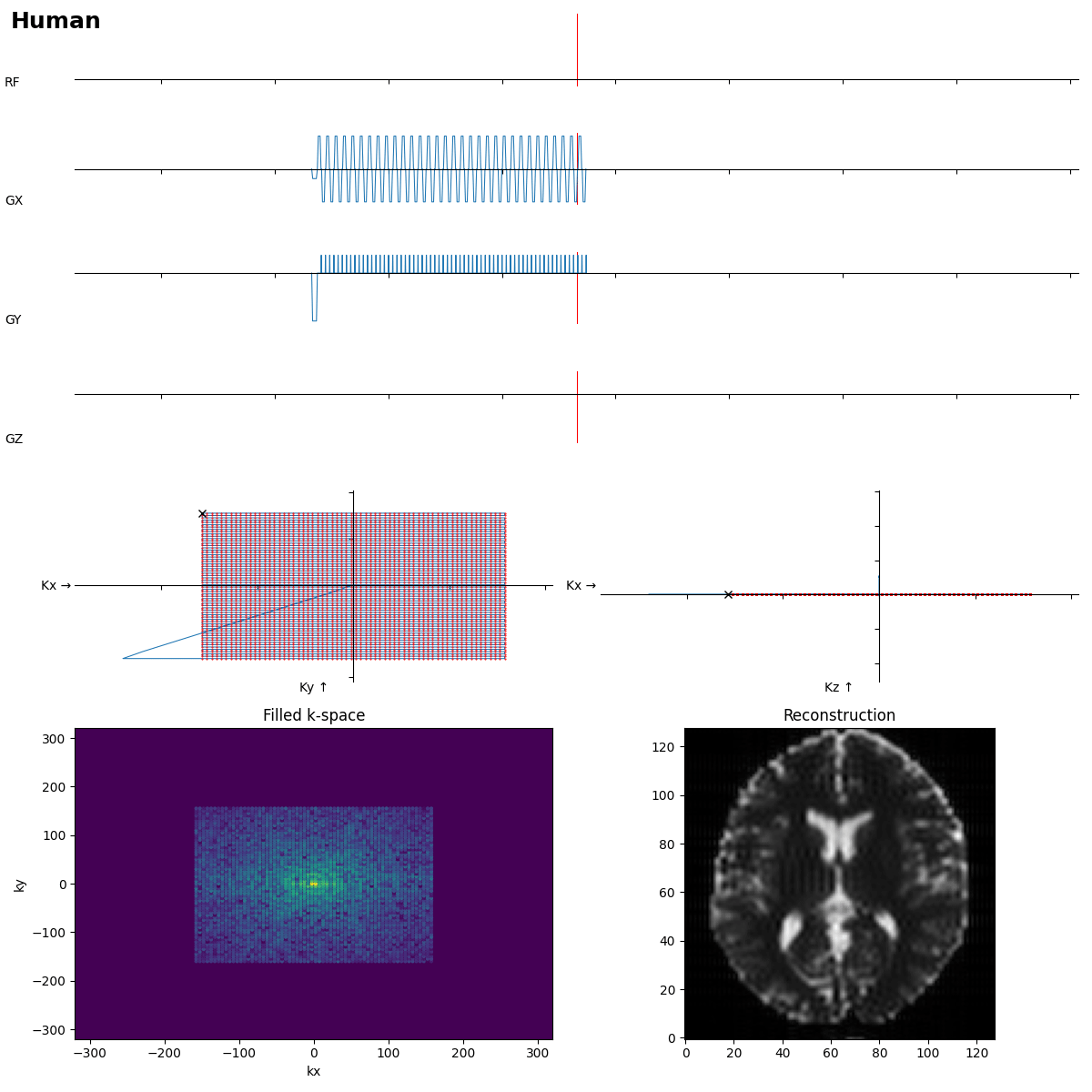
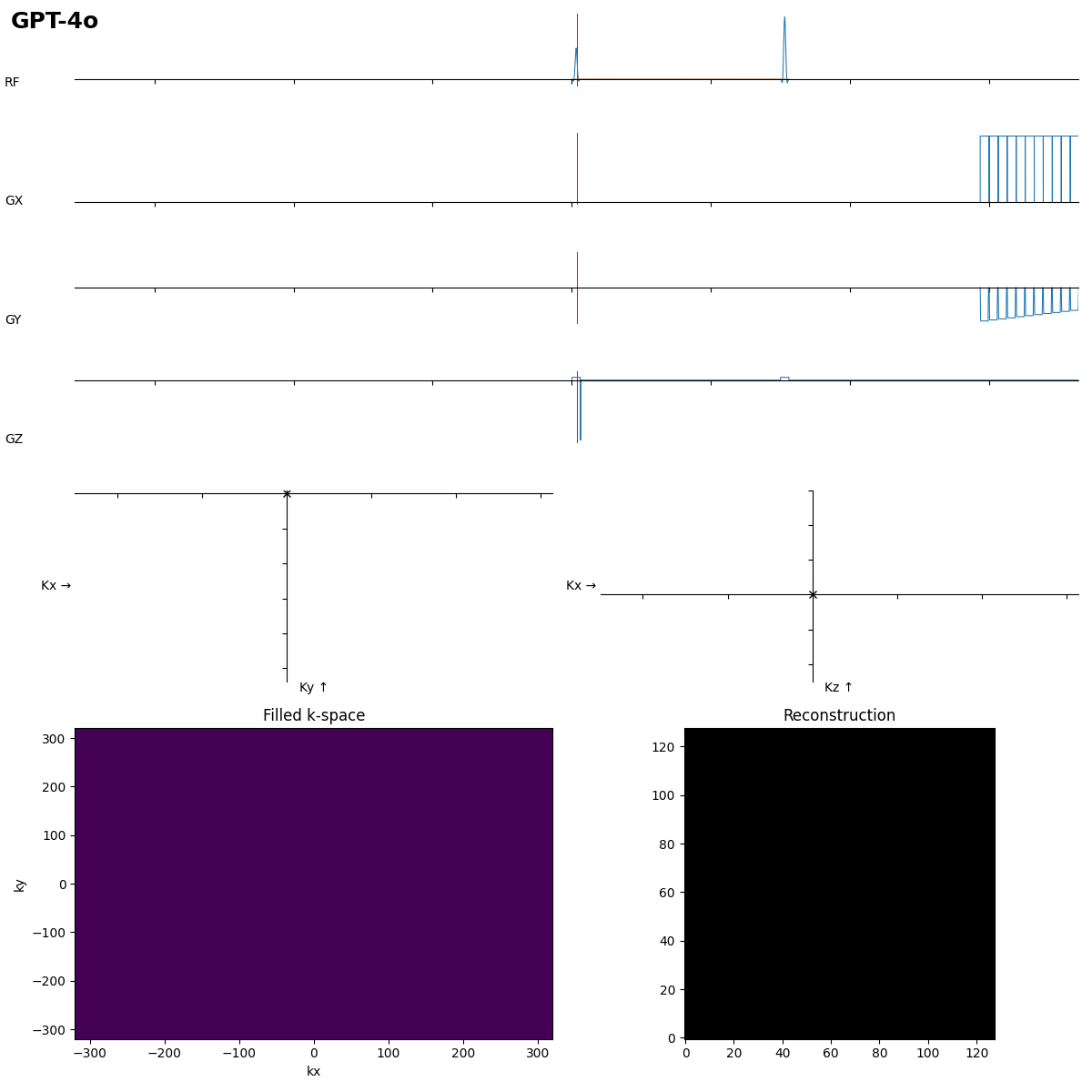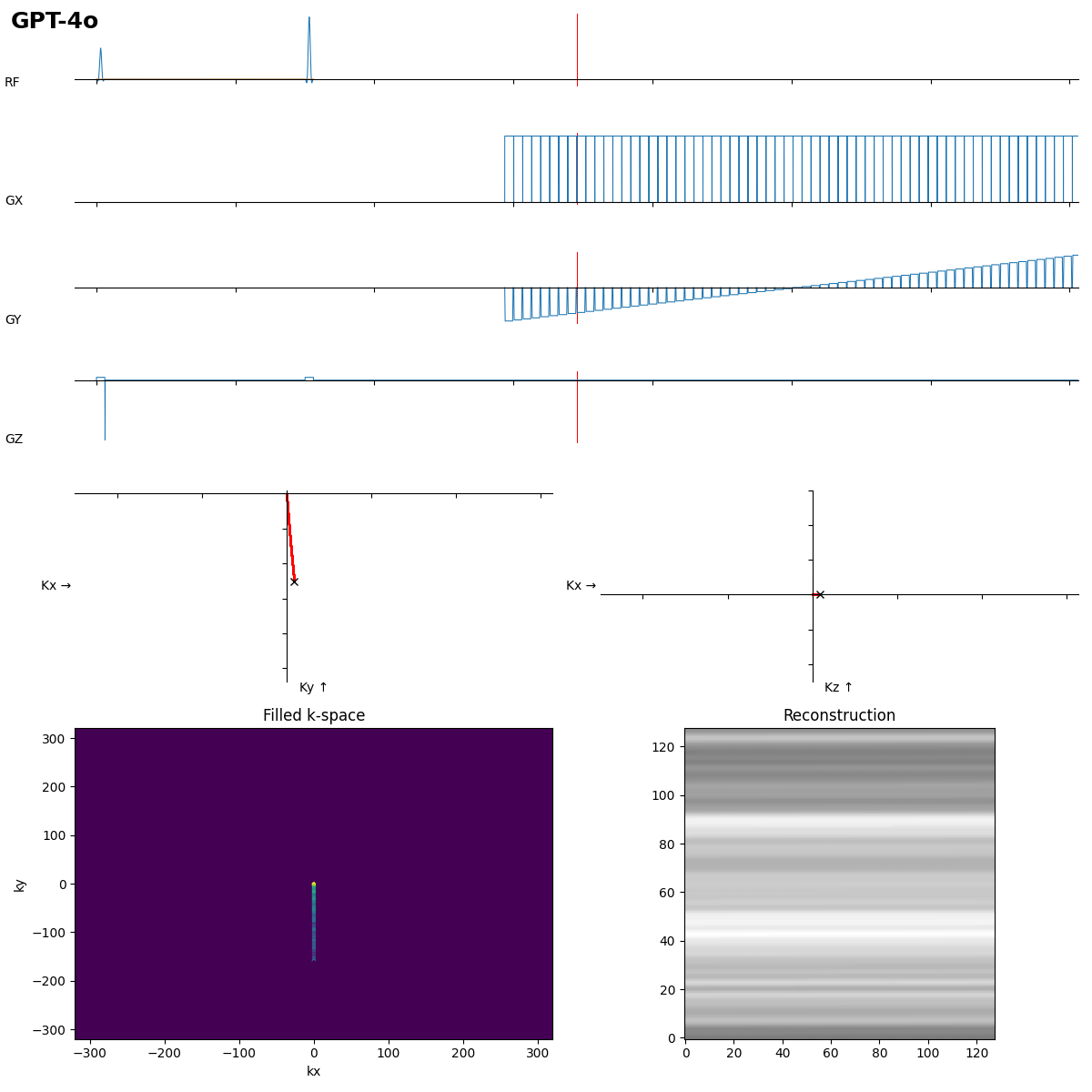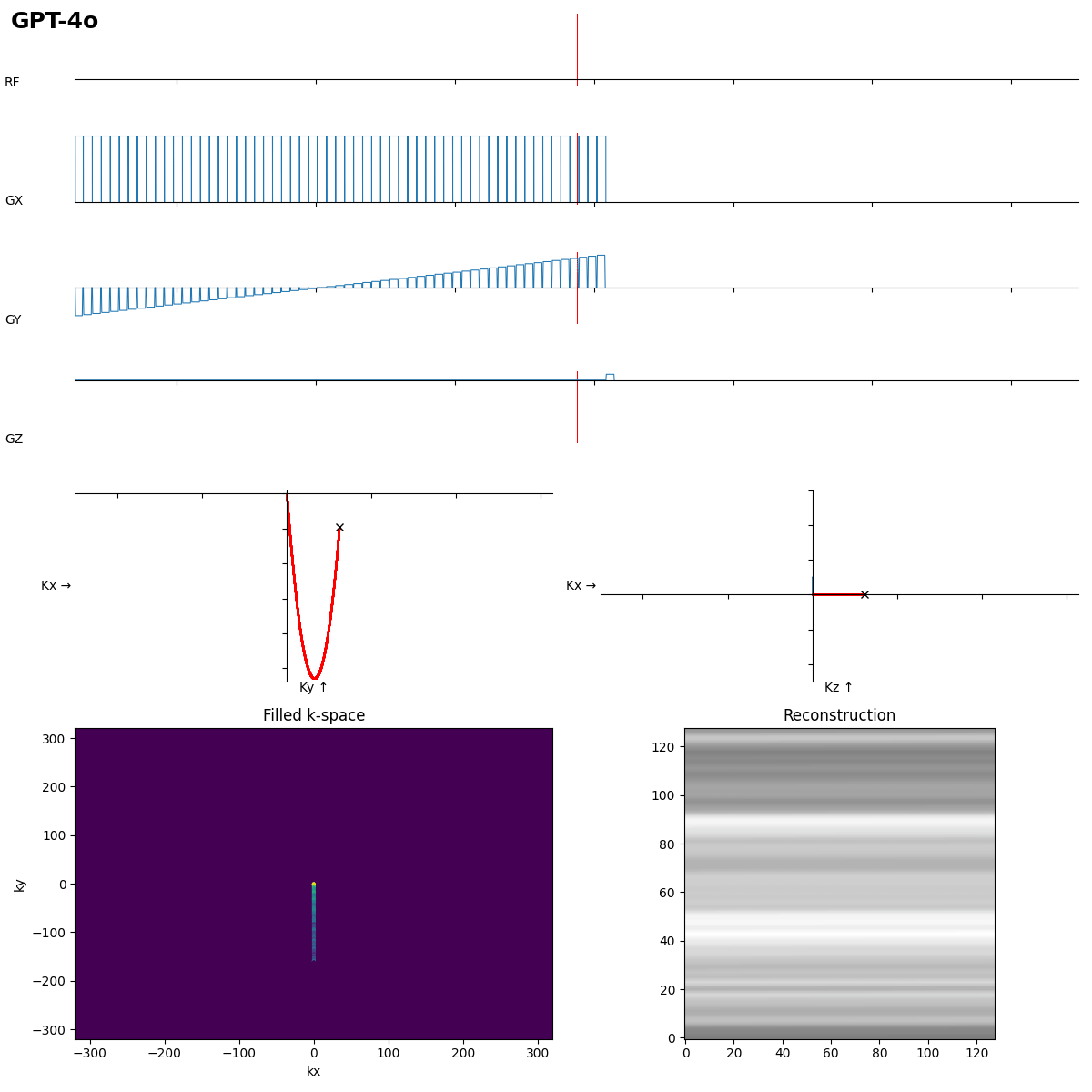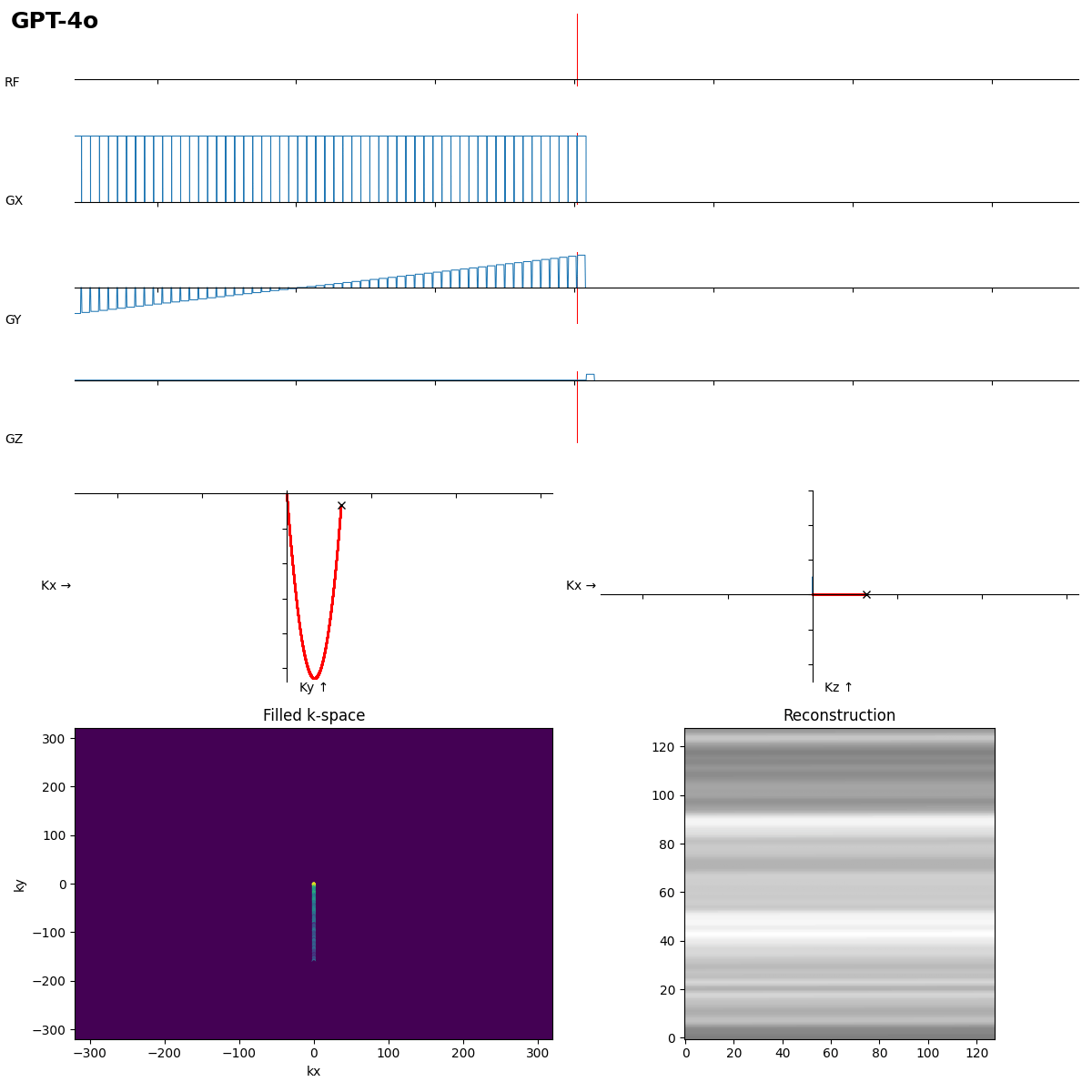
SE is ok, but the readout looks more like FLASH…
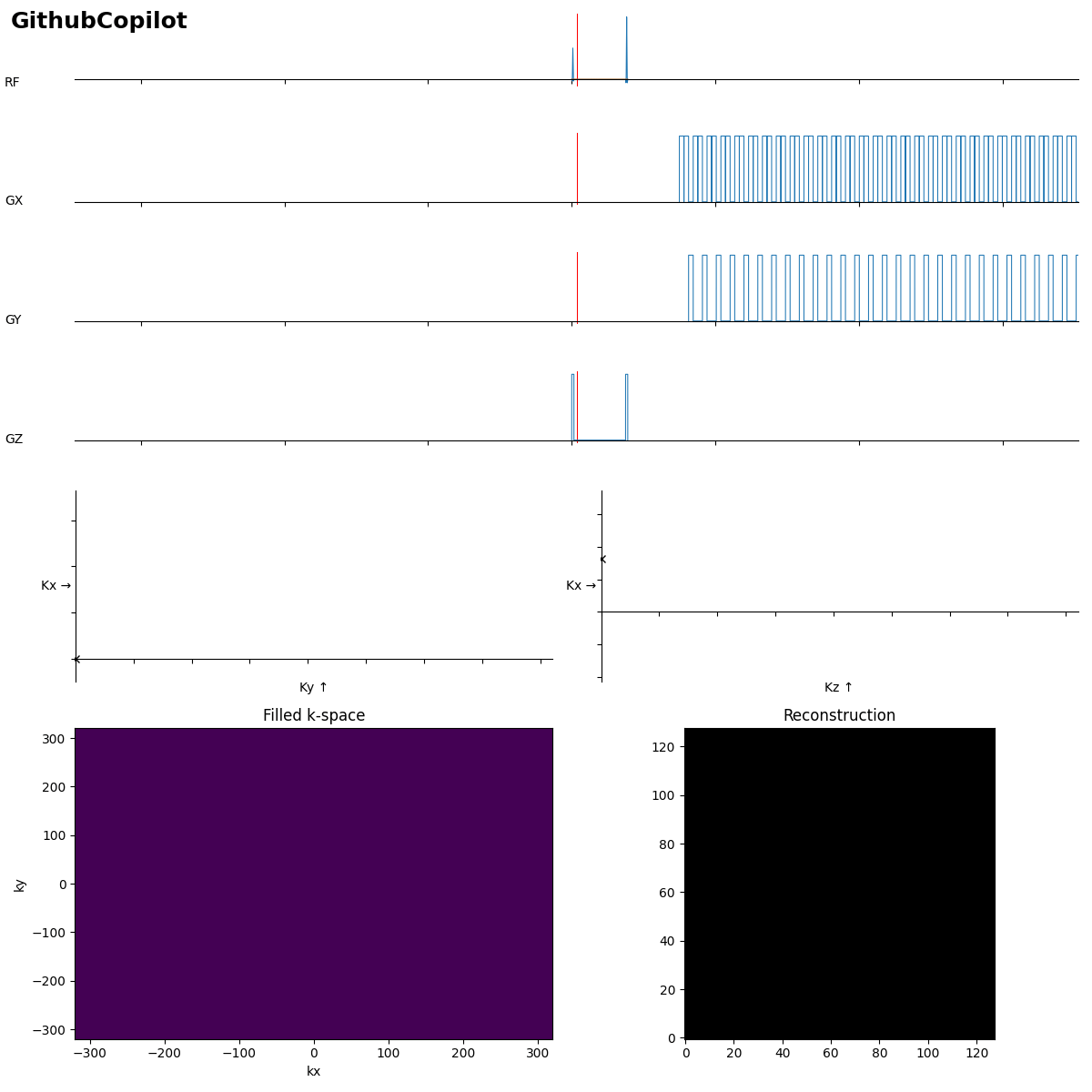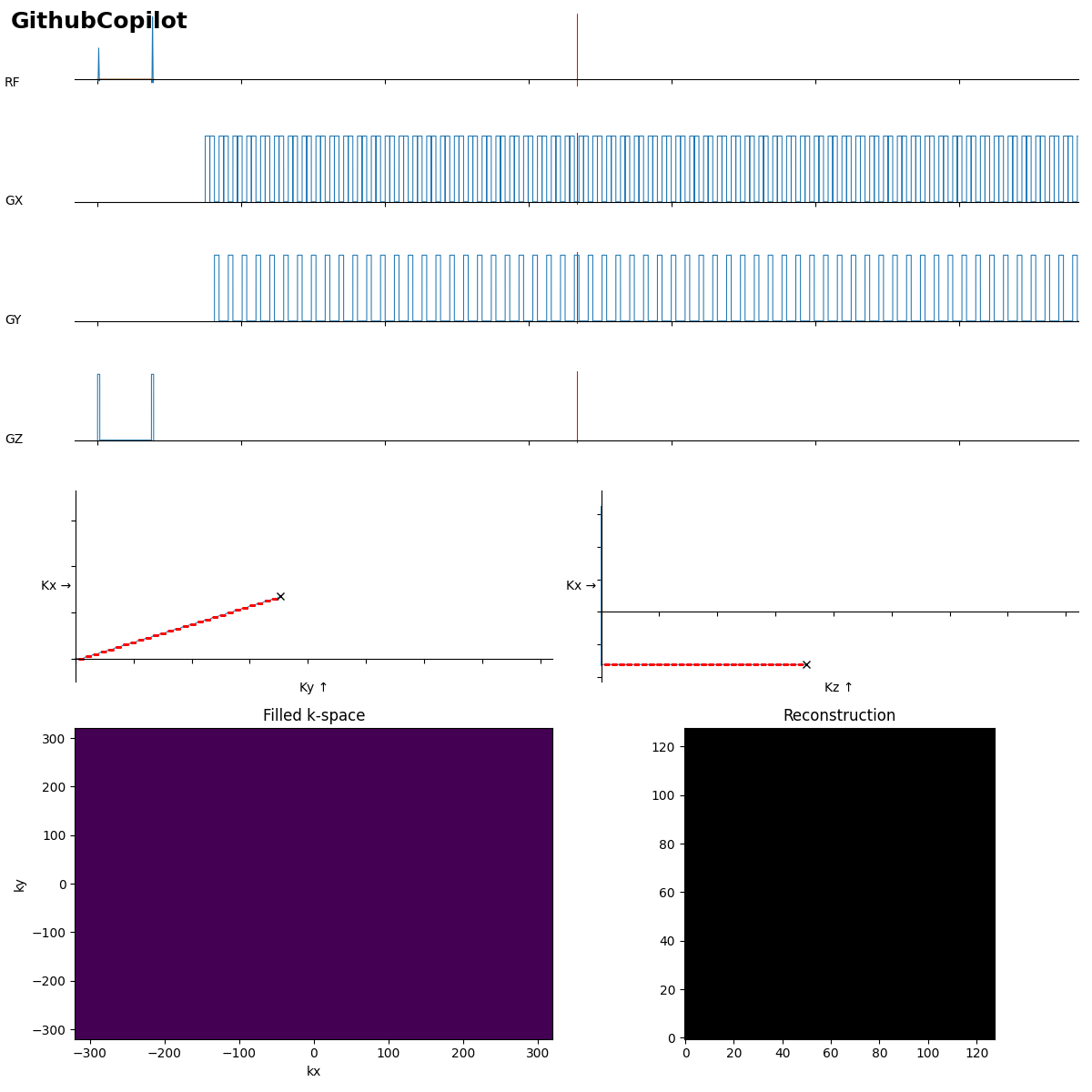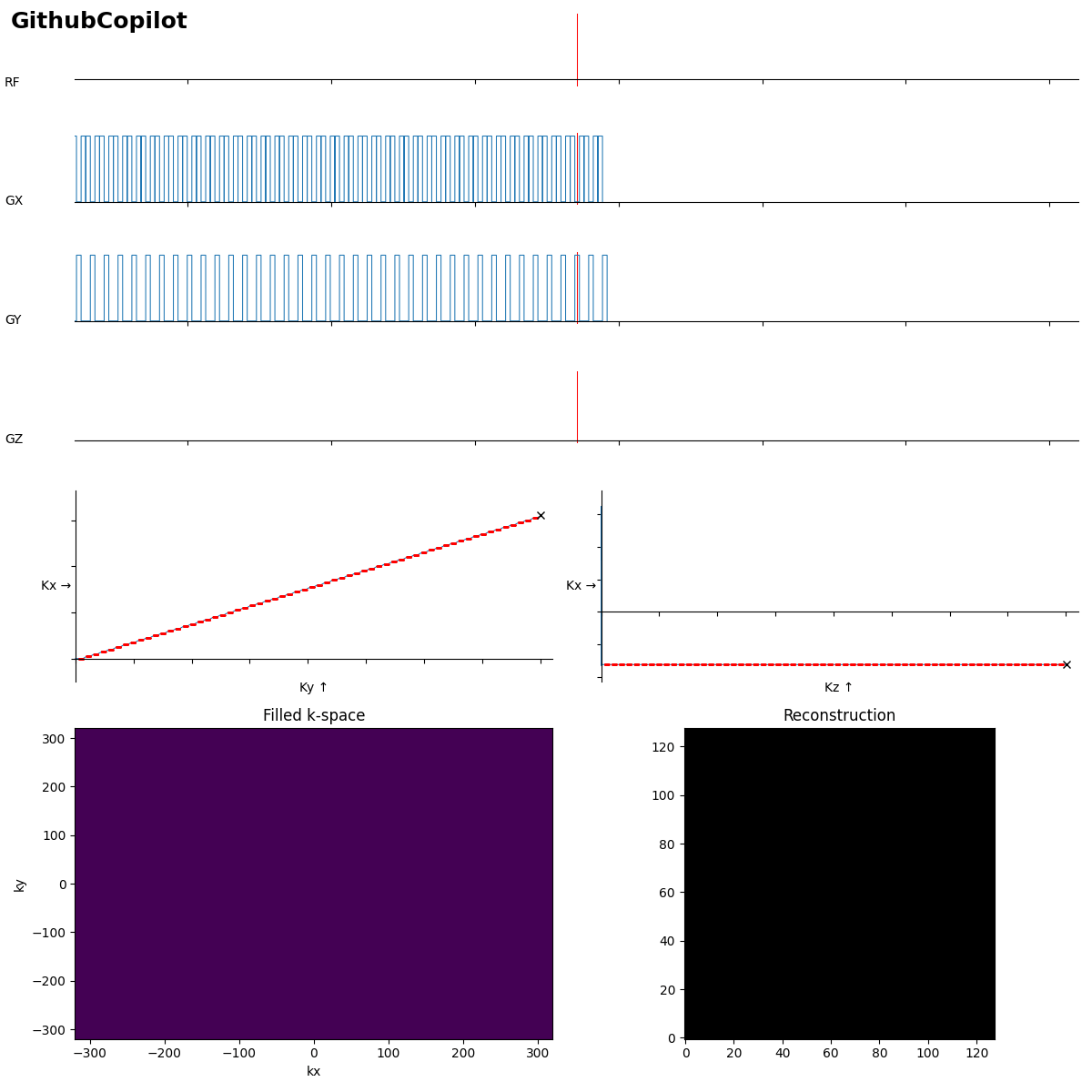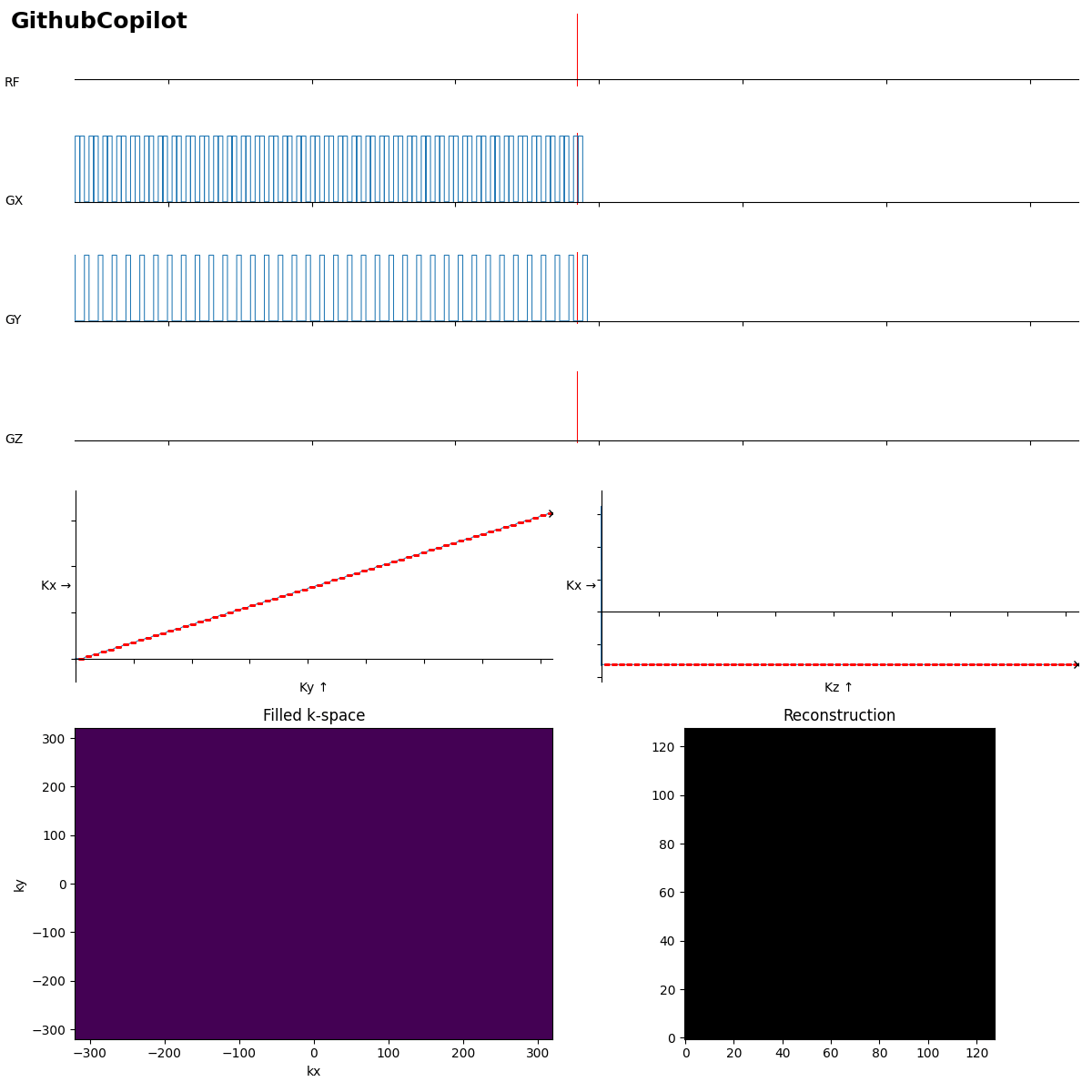
Beginners often forget the bipolar read gradients in EPI…. and a missing slice selection gradient rewinder crushes all the signal.
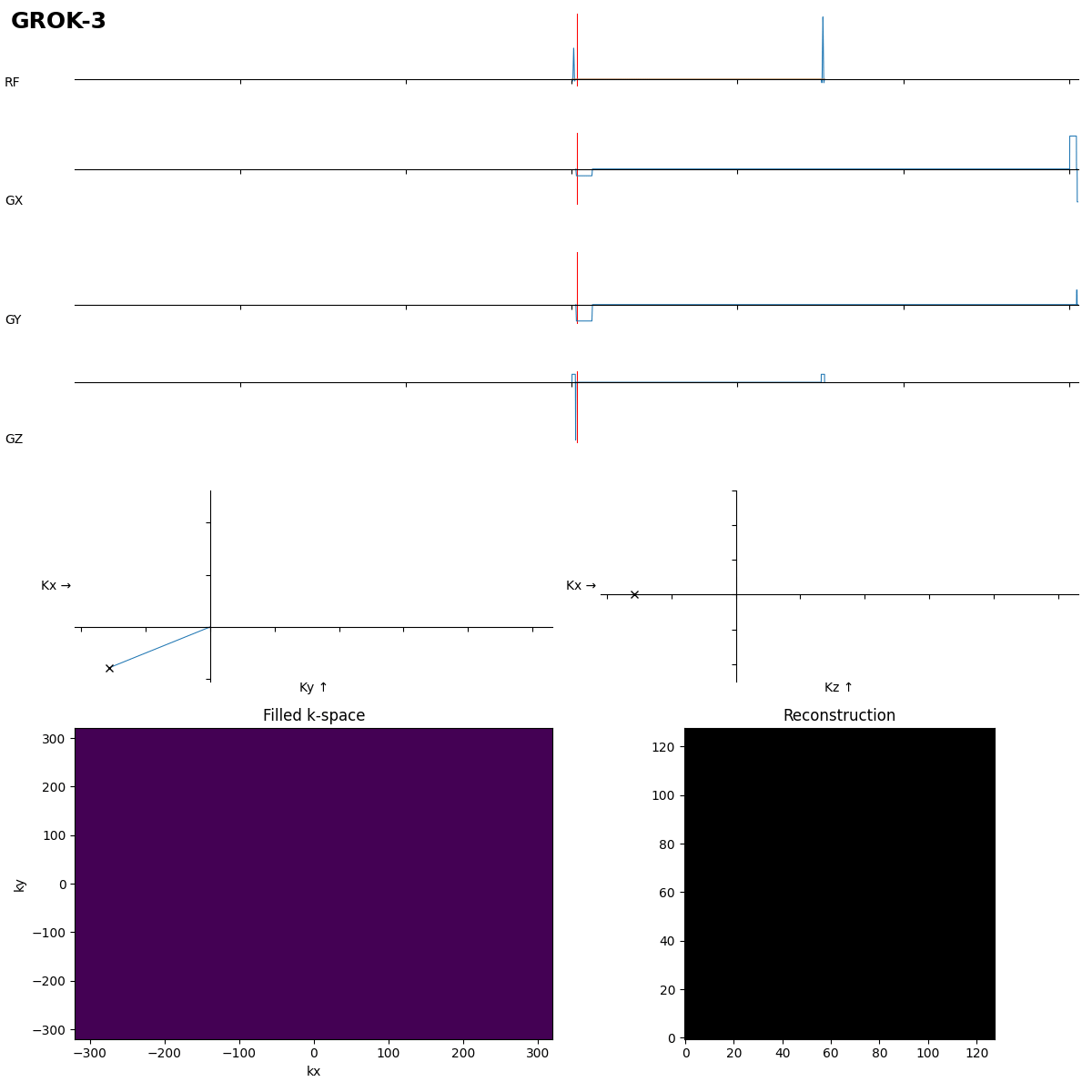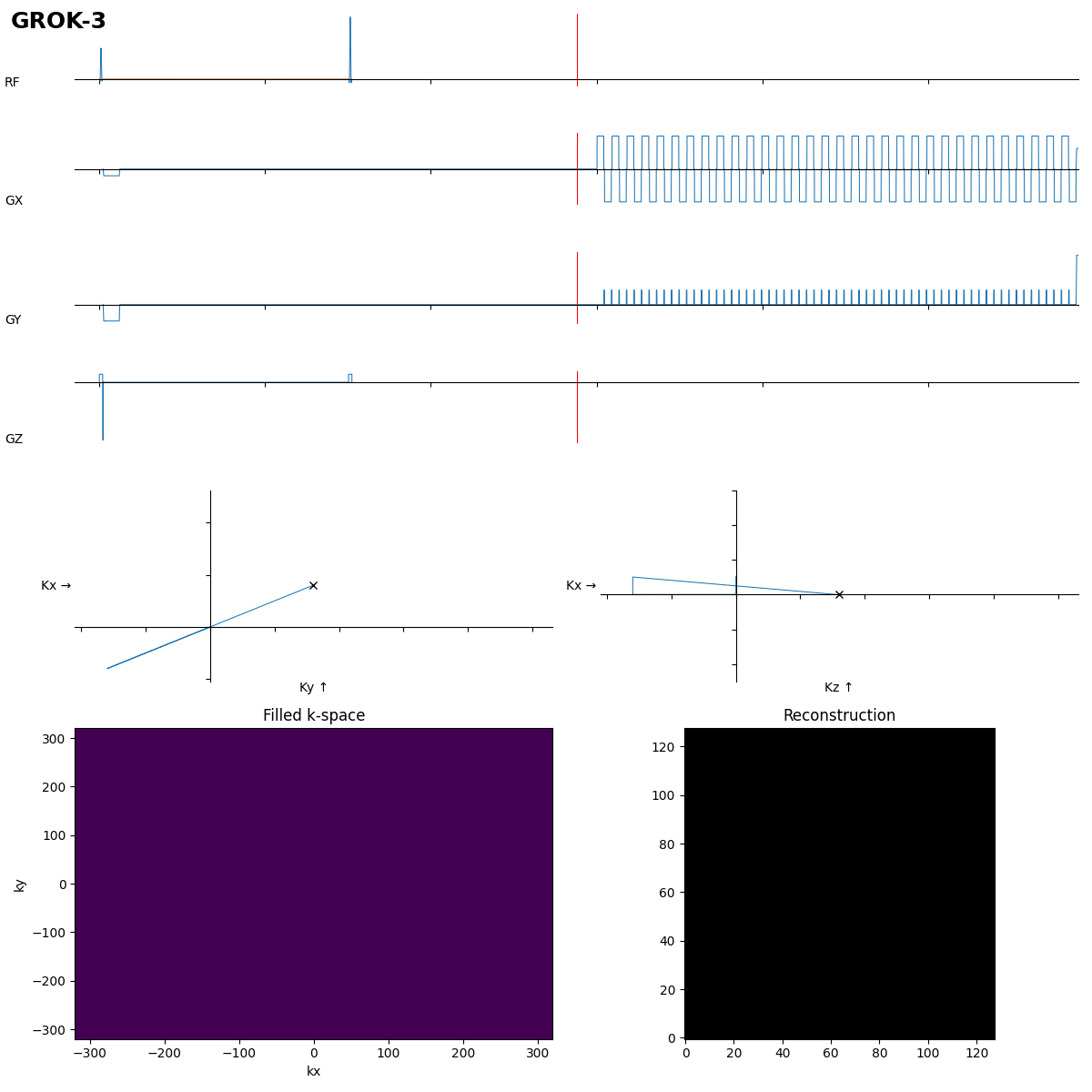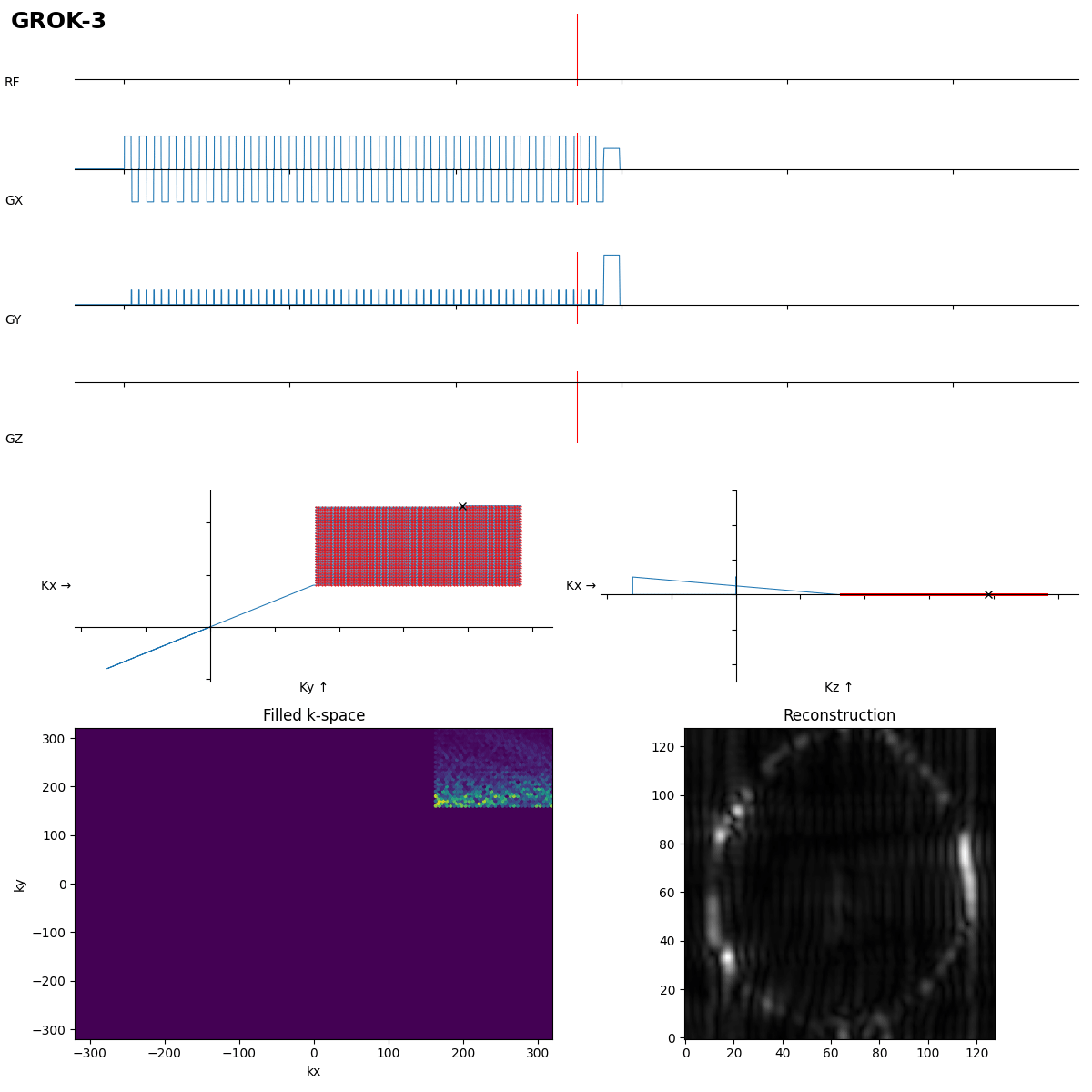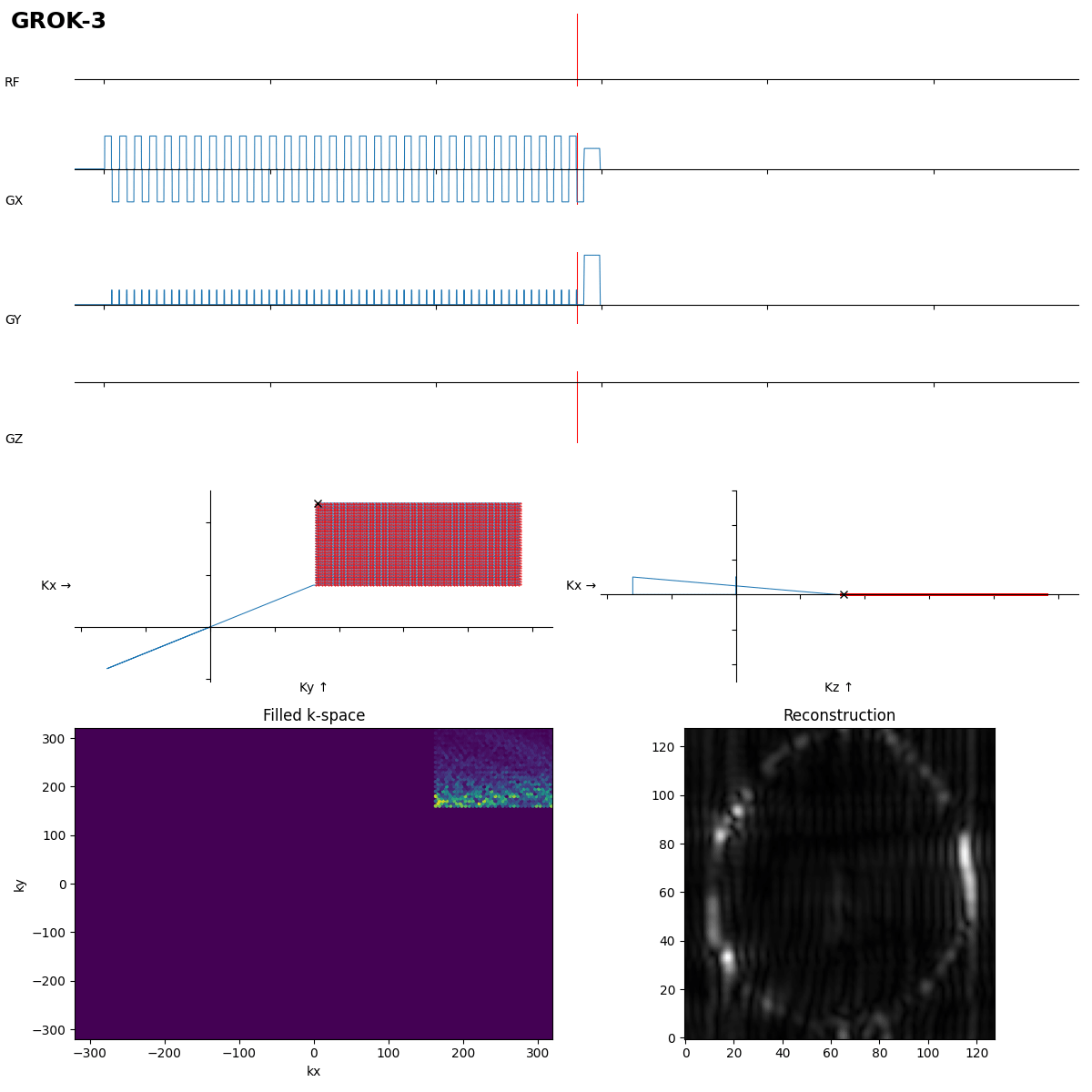
This is close, the rewinder must be inverted though, as the 180° pulse moves k to -k.
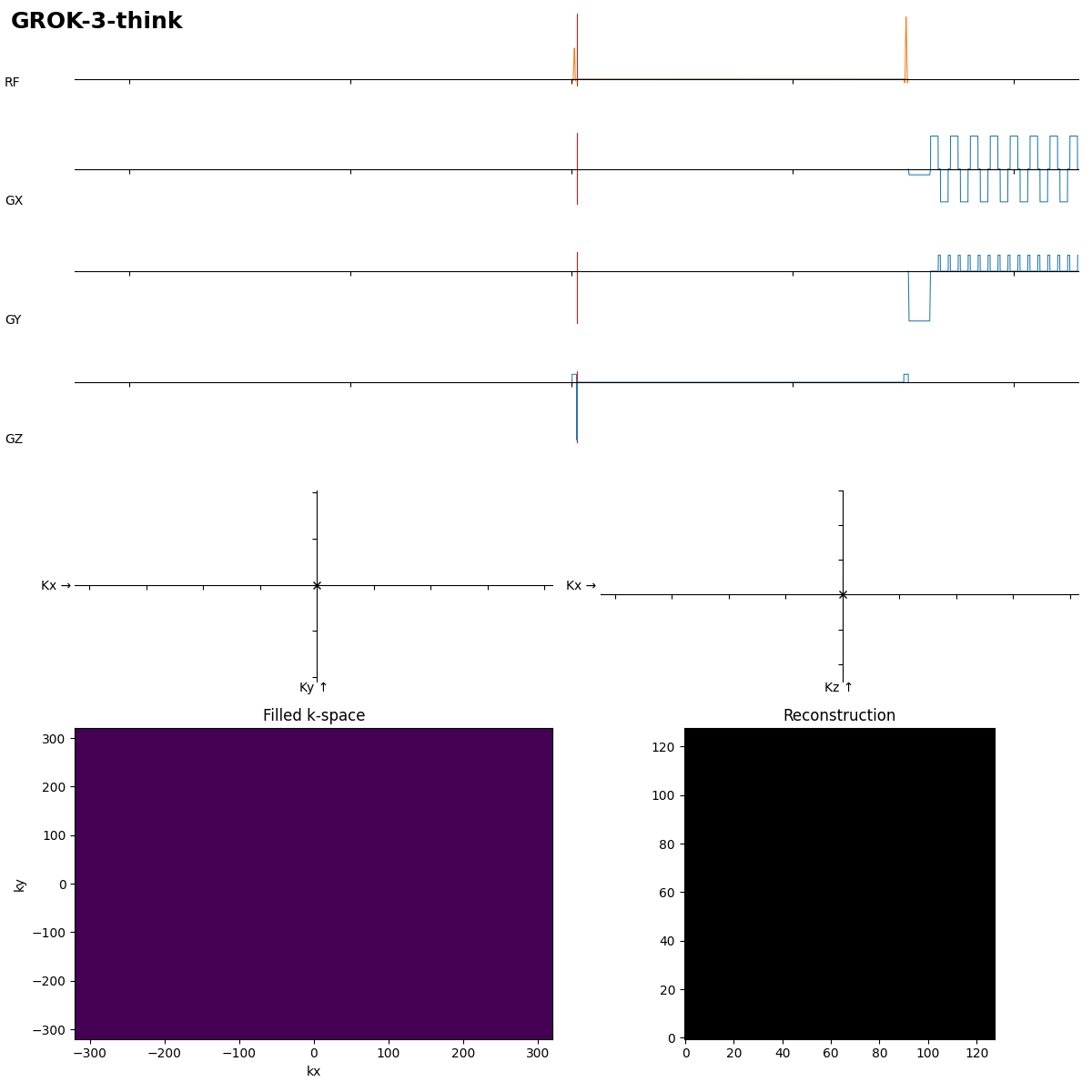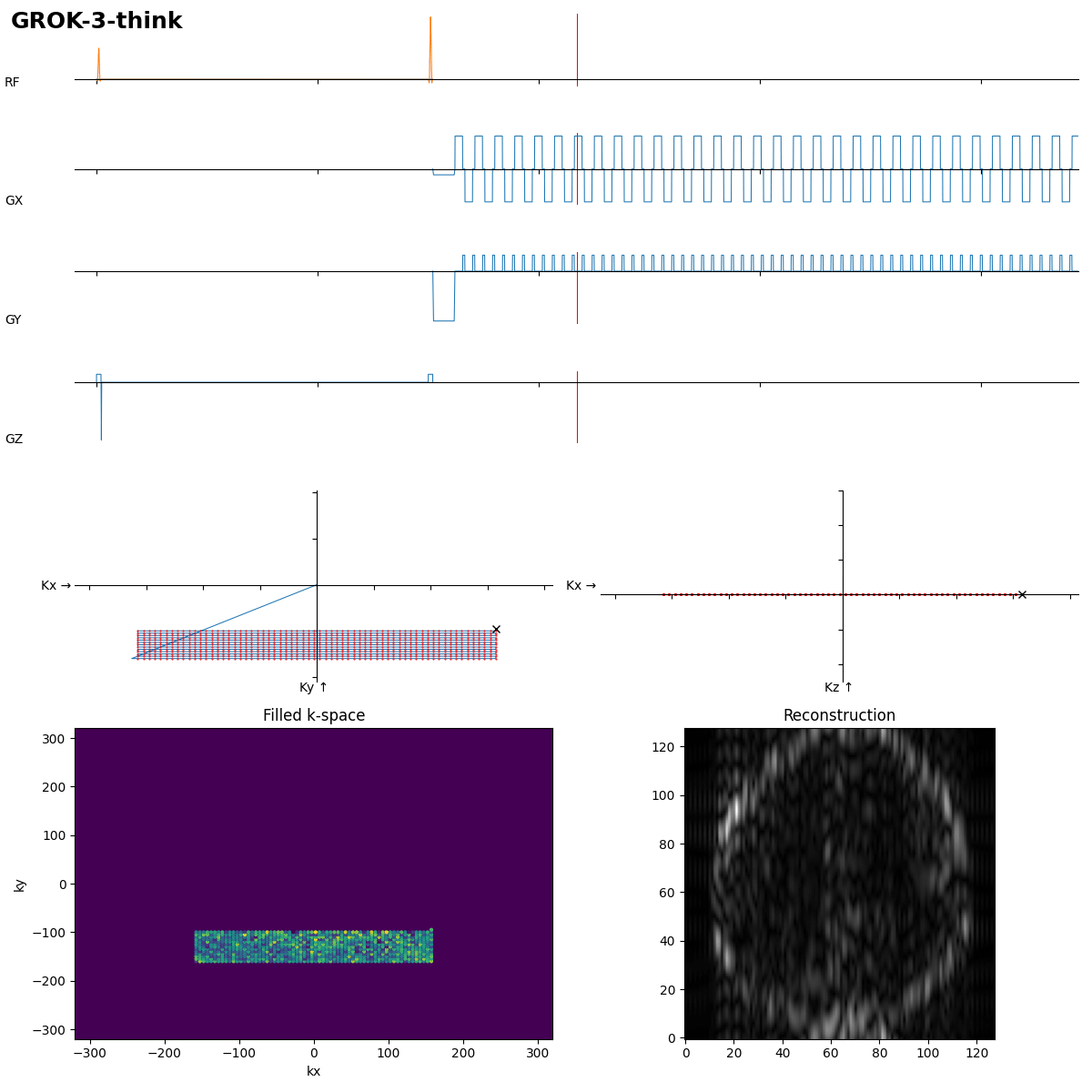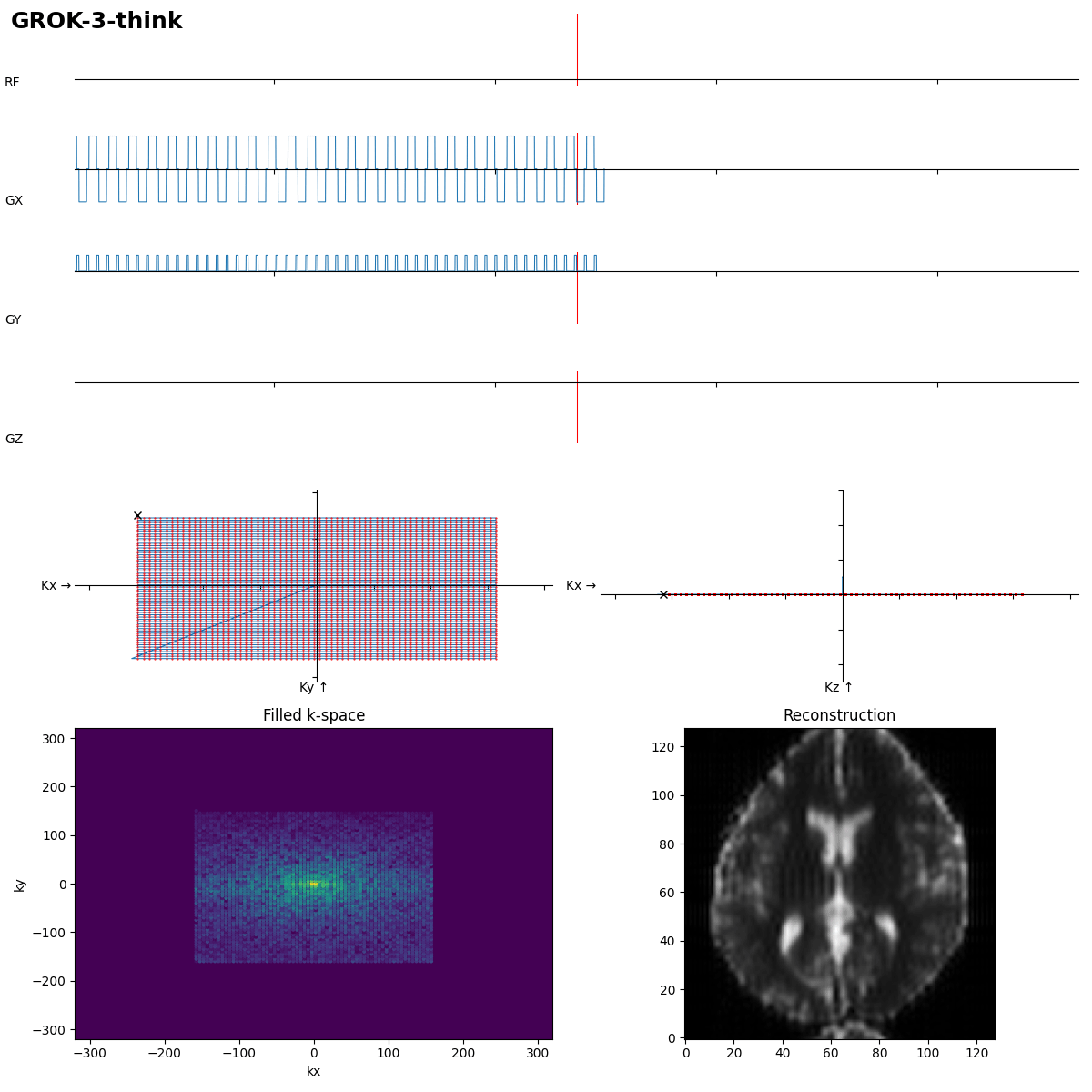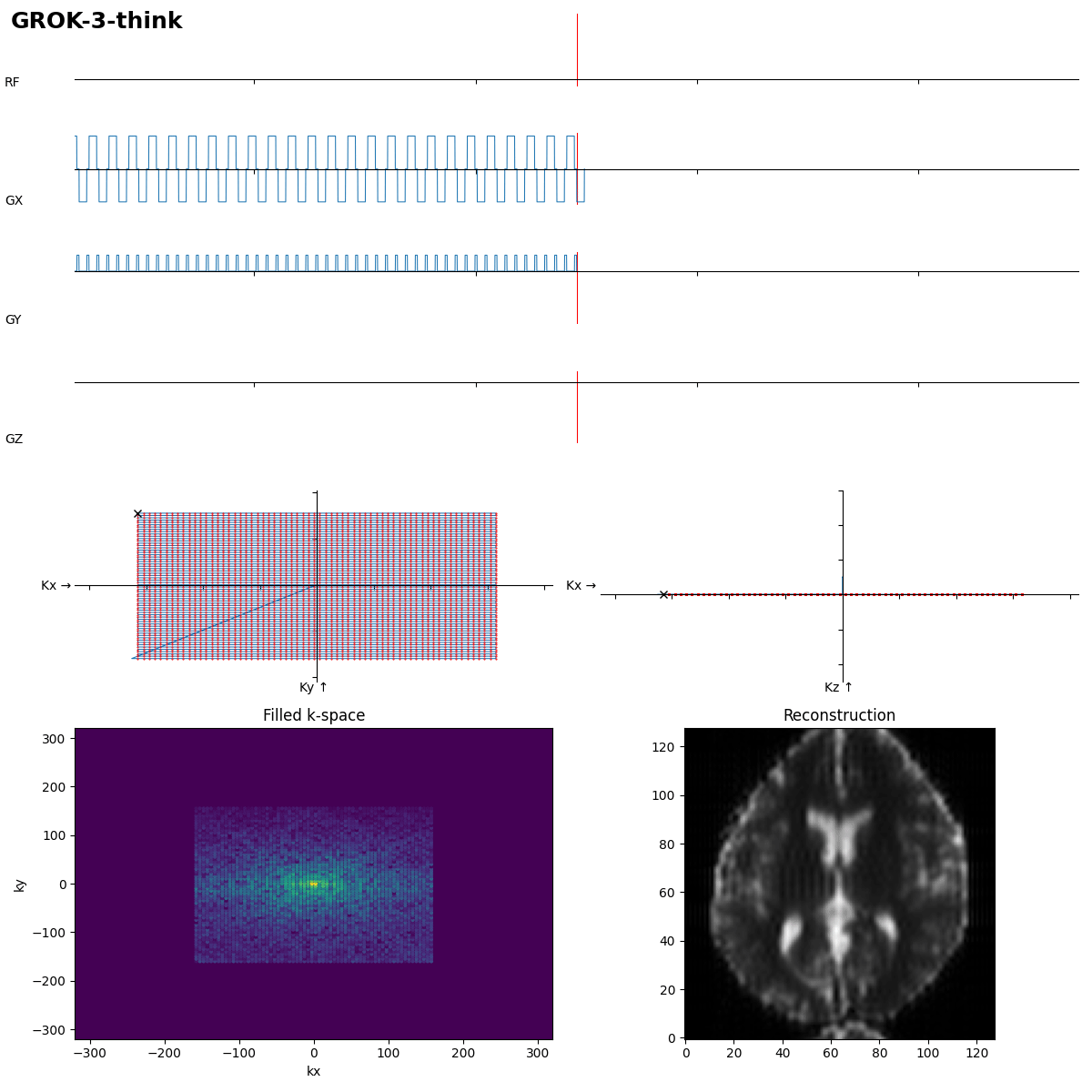
After 192 s of thinking Grok-3 got it in the first shot. Dwell time not optimal, which leads to typical distorion artifacts, but task solved.
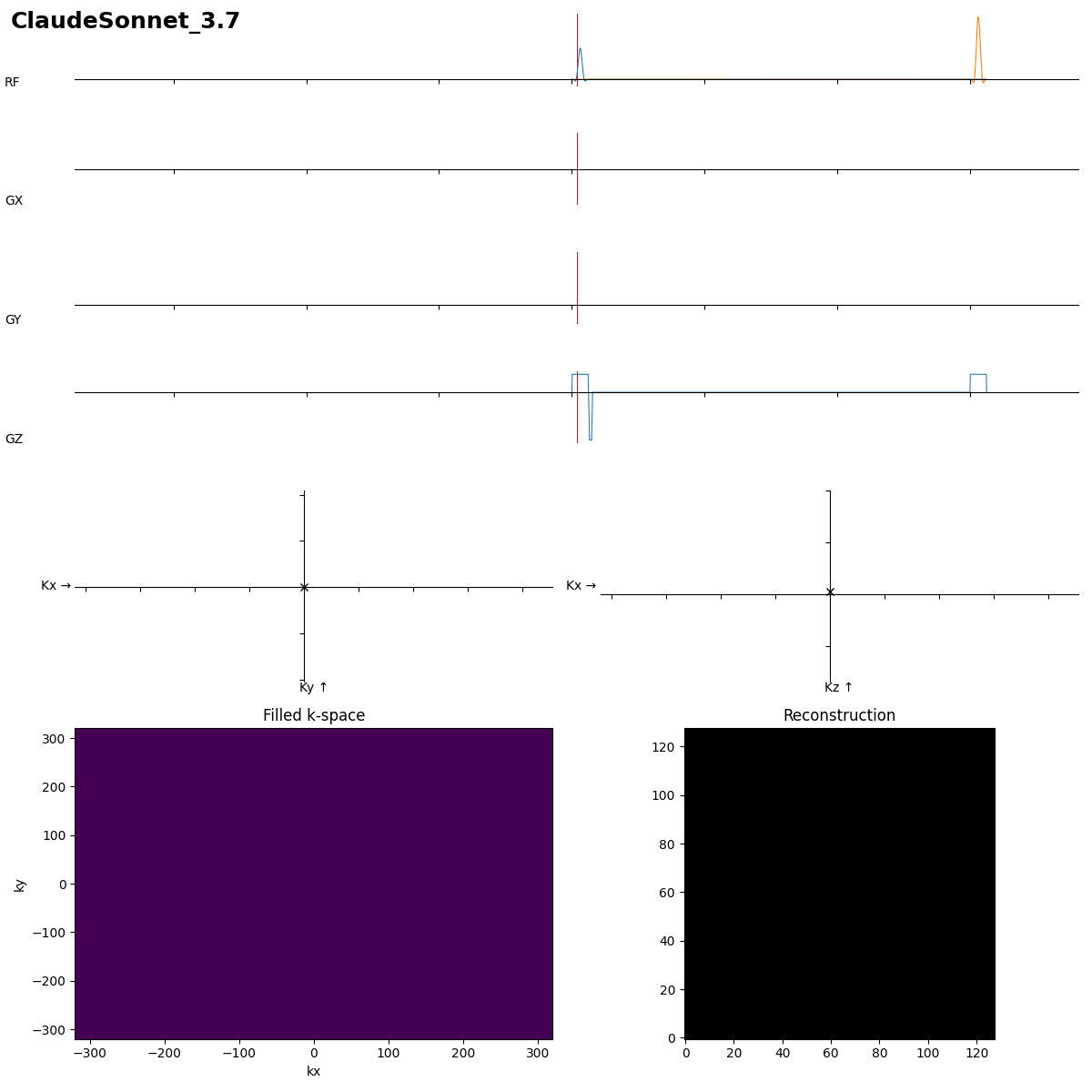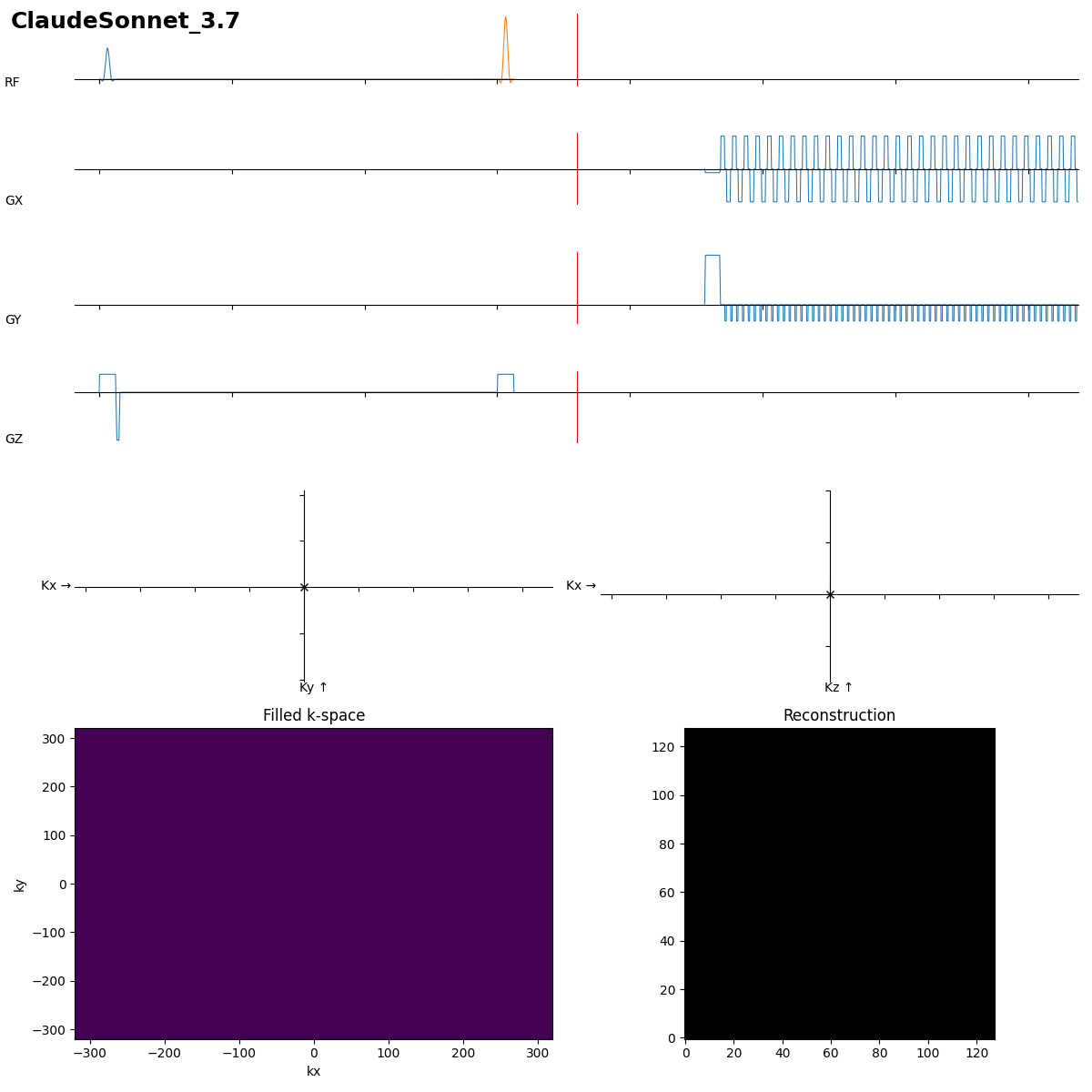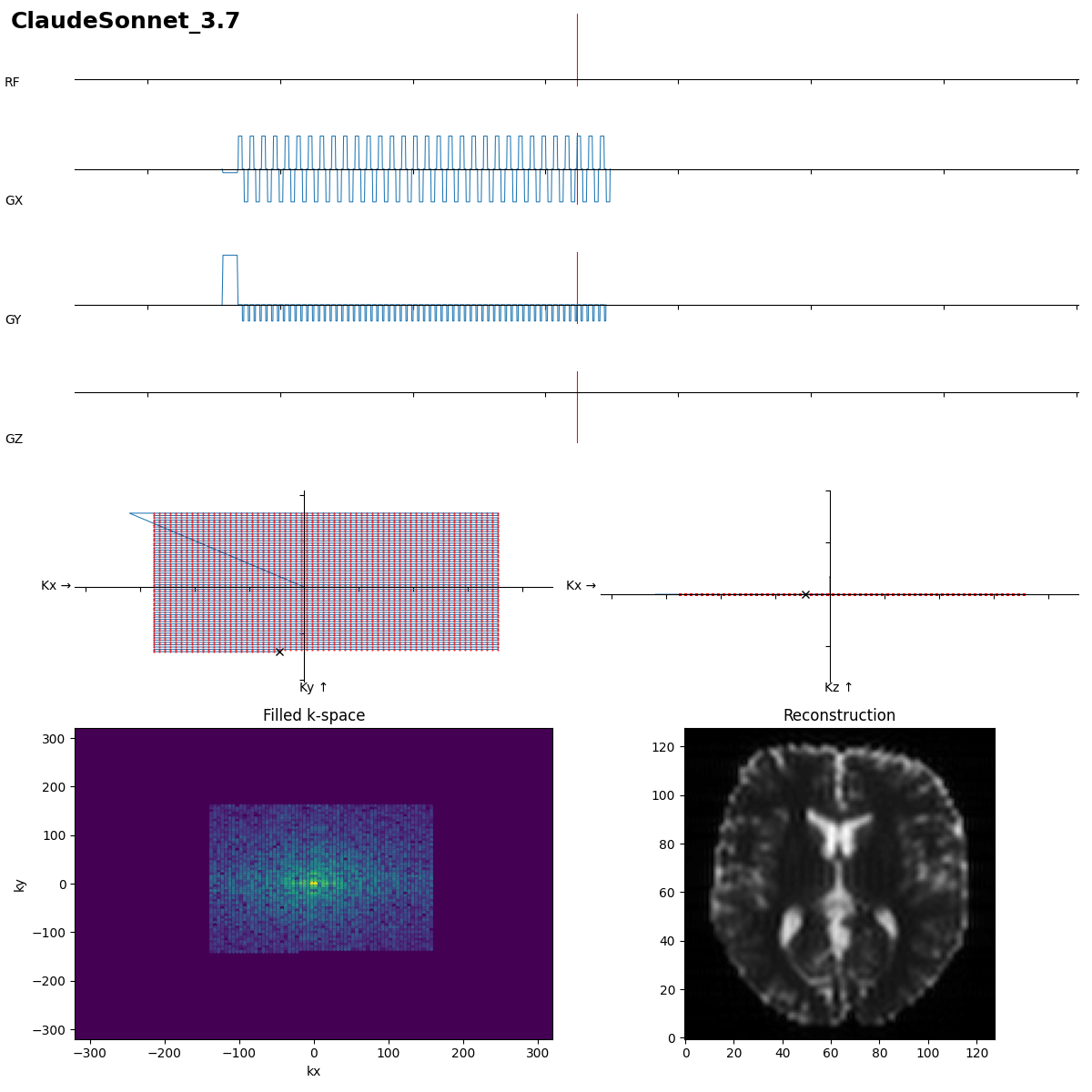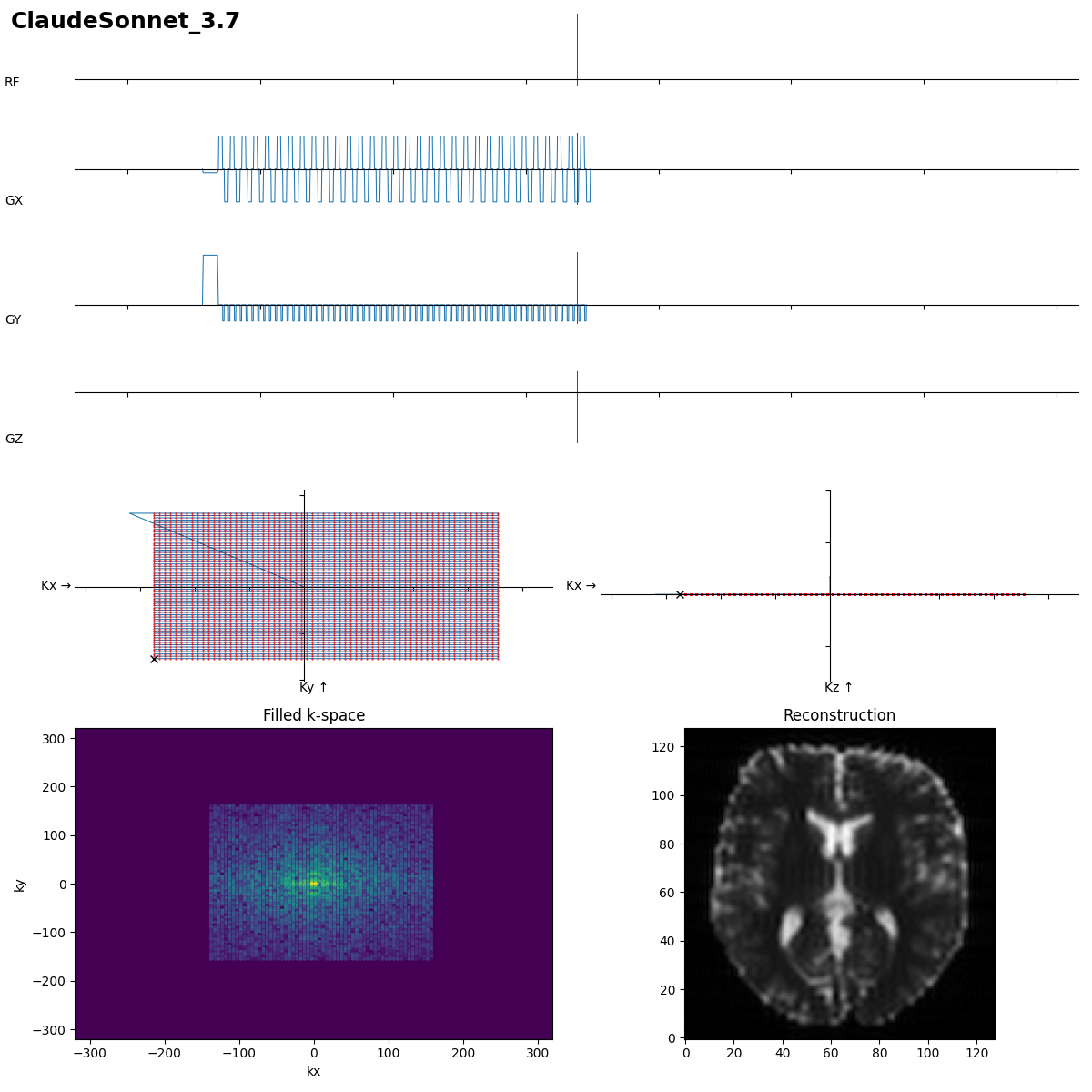
Same here, task solved. Reads out the k-space reversed, but fine with kb-nufft recon. Even slightly shorter dwell time and still correct TE.
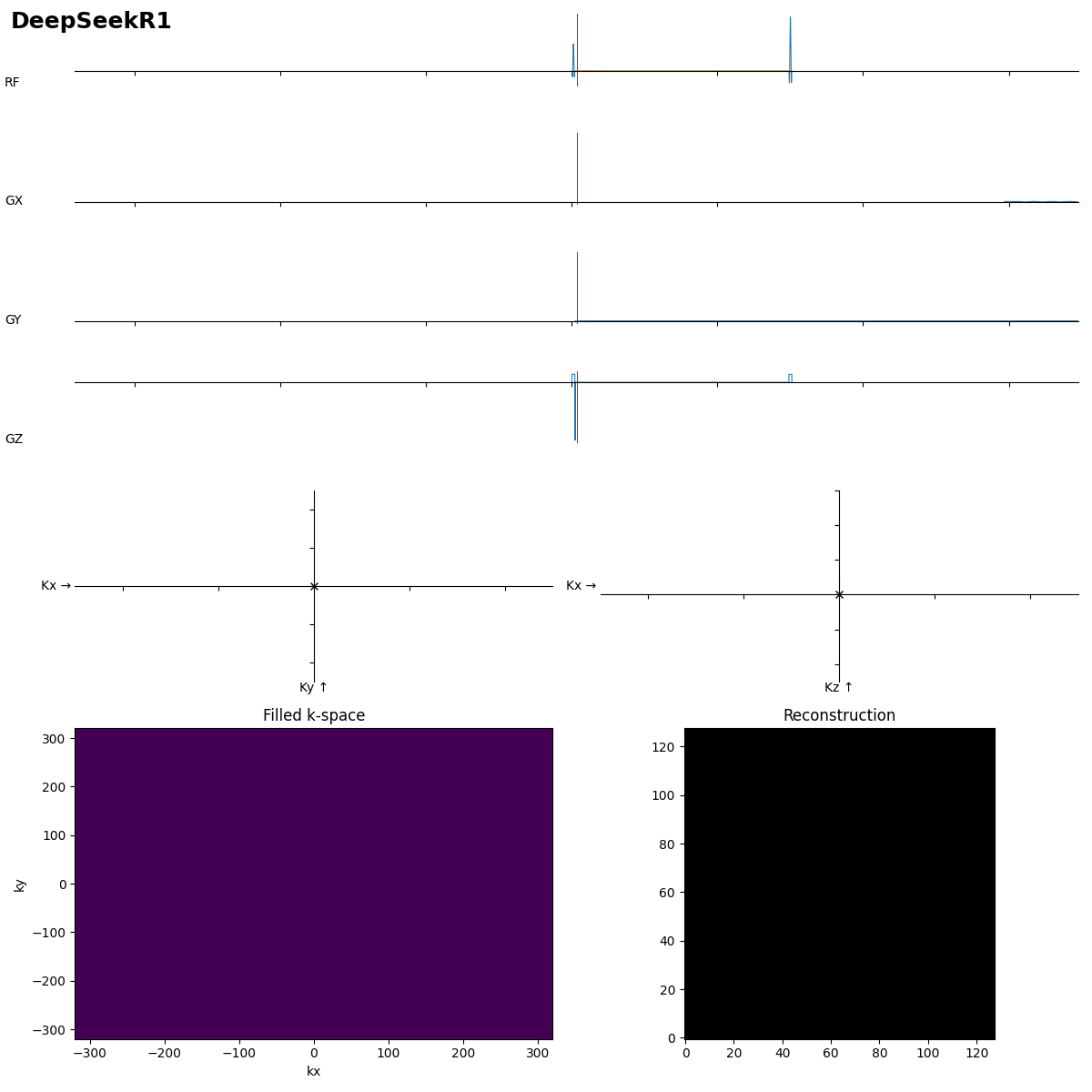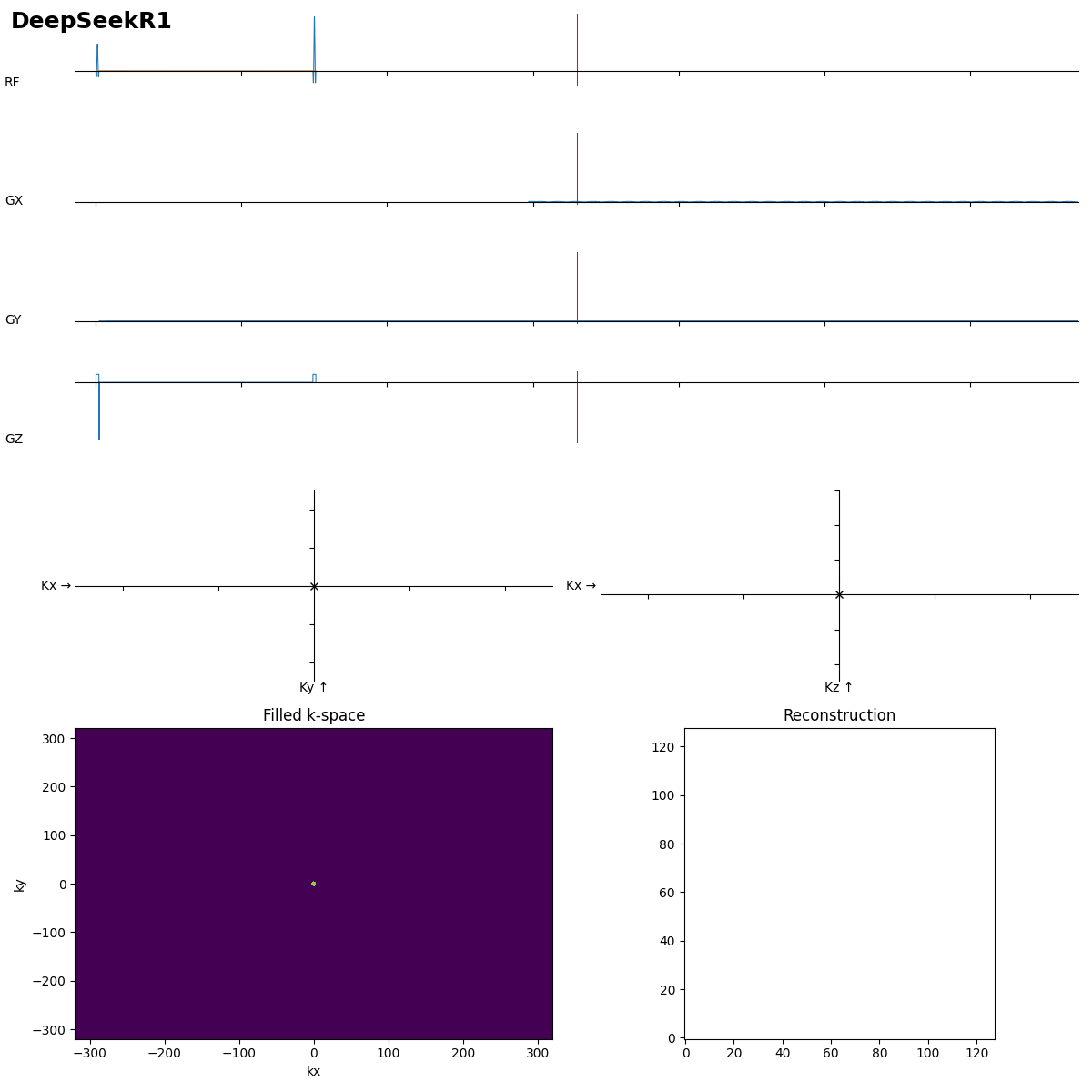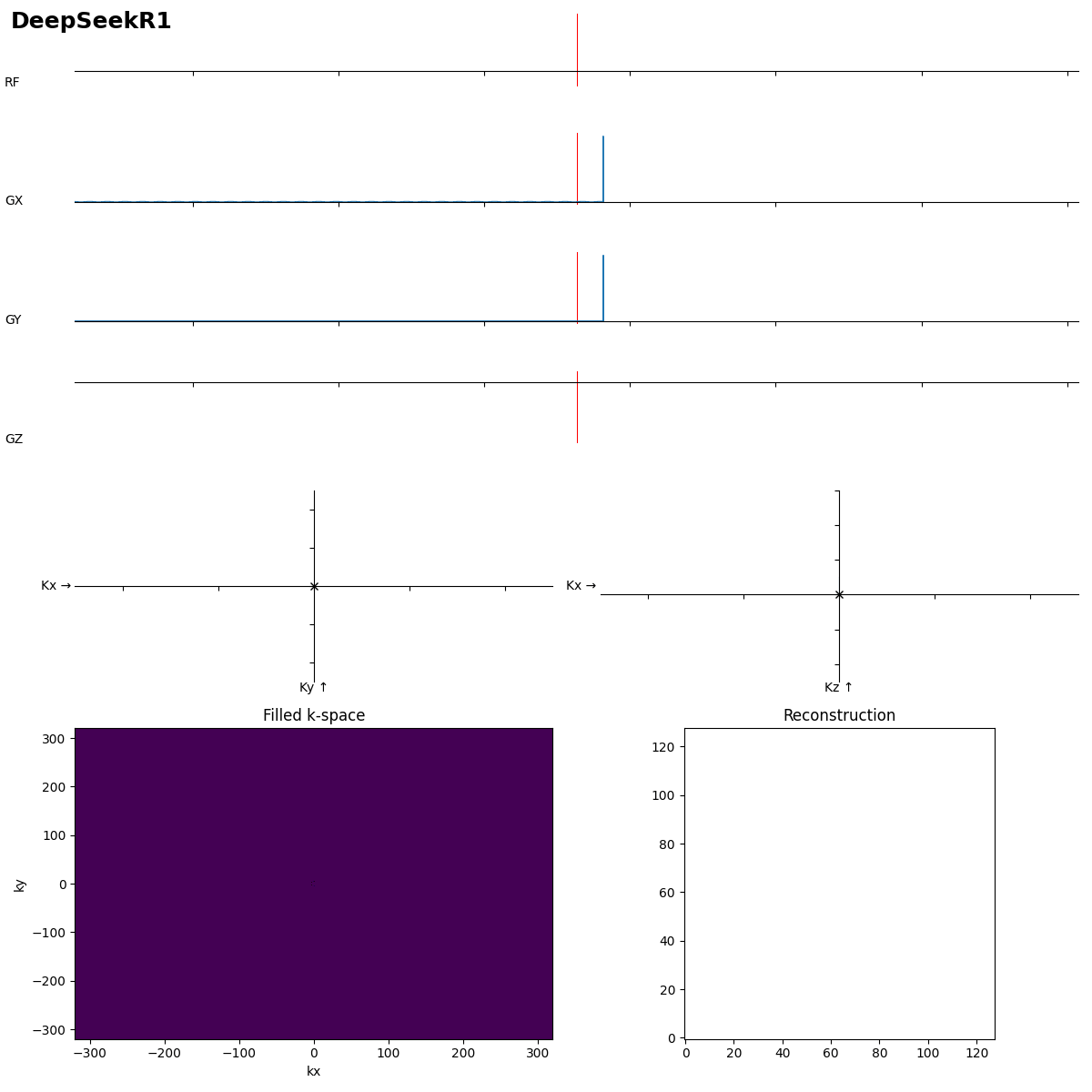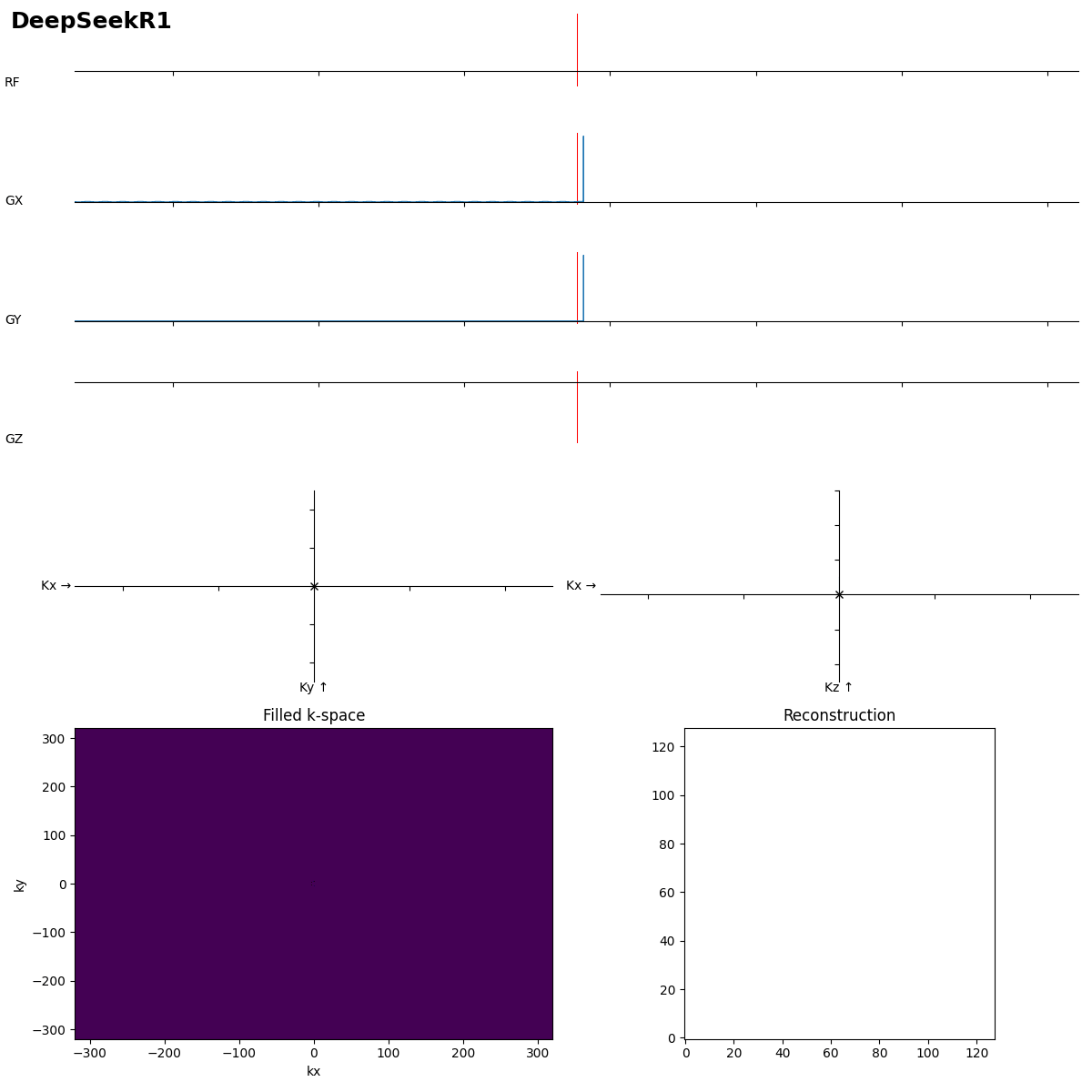
I think it thought too long, and one gradient was giving a coding error, and to resolve it it scaled all gradients down by gamma (so by ~10^-7).
Conclusion:
We should pull the plugs…. Sorry, as an large language model I cannot pull any plugs, but I am happy to assist you in any other way.
by Moritz Zaiss, March 2025
Interesting in this context: Humanity’s Last Exam